Parsing Tables
Representation
The parser looks for one tag at a time. A matching pair, including both start and end, e.g. <table> and </table>, are stored in a single parse node. This same node stores the text before, between and after the tags. These are called the leader, body and trailer, respectively, and are type String.
Should the trailer contain another tag then it is parsed and the result stored in more. Likewise, if the body contains additional tags then these are parsed and the result stored in parts. The result is a parse tree which happens to be a binary tree where parts is the left subtree and more is the right subtree.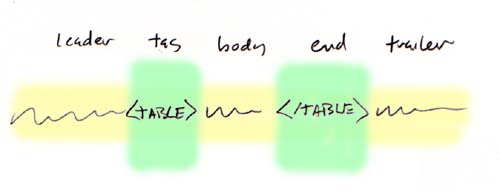
In this diagram the parts references are shown as arrows shaded green while the more references are show as arrows shaded yellow. A depth-first traversal visits each cell in the natural reading order of top down, left to right.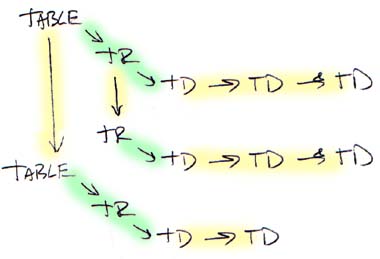
Limitations
For simplicity parsing uses String's indexOf function. This could be fooled by tags embedded within strings or comments. We can easily substitute a stronger parser. But right now we are just testing HtmlSamples.
The search for matching end tags does not consider the possibility of a nested tag by the same name. For example, html allows tables within (cells of) tables. This situation occures when, say, wiki uses a table to organize the page into columns. See WikiRunner for our simplistic solution.
Design Considerations
The following discussion is from an email dialog regarding the absence of collections in the parsed html.
I find myself rarely using java collections anymore. Instead I make objects that include references that could easily be called "first" and "rest" which you may recognize as the sanitized versions of "car" and "cdr". -- WardCunningham
['Car' and 'cdr' are the functions that access the two pointers in a lisp 'cons' cell.]
This is interesting. I'd love to see a short or extended example ofthis ... though I'm sure that what I'll invent from this remark will be just as interesting. -- RonJeffries
... Recently I've been parsing html for test data and needed a "DOM" that I could annotate with test results. The "reusable" DOMs are incredibly complex, having become an industry in their own right (see Dijkstra's comments about industry in the EWD memo cited by Hill.) I ended up with a single class, Parse, that represented parsed html elements of interest and had references, "parts" and "more", which lead to other elements either contained within or subsequent to a particular element. I grab test data from html files this way.
String interest[] = {"table", "tr", "td"};
Parse tables = new Parse(input, interest);
The unescaped text of the first cell of the second table could be
reached with either of the following.
String cell = tables.more.parts.parts.text(); String cell = tables.at(1,0,0).text();The second form is just syntactic sugar for the first. (Note: tables.more.parts.parts => (cdaar tables) in lisp) The code I write tends to be more stepwise than either of these examples because there are little bits of work to be done along the way. Still, the work codes out nicely and even leaves some room for the type checker to contribute.
Some would argue that I have given up the opportunity to substitute various collection implementations when I code without adhering to a standard collection interface. I understand this argument intellectually, but I don't think it holds up in practice, especially in java where the code bloats with the mechanisms required to support collections. Let form follow function, not dogma. -- WardCunningham
I actually came up with a similar binary tree solution when I tried to build a Text to HTML converter. I parsed the text into a binary tree and then rendered the tree out adding HTML syntax on the fly. I think the only confusing part of the Parse class is that it is not immediatly clear which is the right and left leg of the tree. 'more' is the left node and 'parts' is the right node. -- GarethFarrington
What's a DOM? (Document Object Model?)
If all we needed was the value of text() for the table cells, then a table could be a list of rows, a row could be a list of columns, and a column could be a list of cells. Instead, we need to be able to reproduce the entire HTML file; for that, we need stuff other than the cell value (that is, leader and tag and end and trailer, not just body), and I don't think there's any good way to represent that with a list-of-lists.
Some of the methods (last(), leaf(), and especially size() and the various at() flavors) make me (PSRC) uncomfortable. It seems as if the point is to implement an array (with what should be O(1) operations) by using a singly linked list (and O(N) operations). I don't care about better runtime efficiency in this case; but I would like an abstraction whose interface was in better harmony with its implementation.
(I think at some point I got "more" and "parts" mixed up.)
If anyone needs one, here's a way of showing what a Parse object looks like:
public String toString() {
if (parts != null) {
if (more != null) {
return "("+parts.toString()+"), "+more.toString();
} else {
return "("+parts.toString()+")";
}
} else {
String bodyPart;
if (body != null) {
bodyPart = text();
} else {
bodyPart = "";
}
if (more != null) {
return bodyPart+","+more.toString();
} else {
return bodyPart;
}
}
}
No Parse node ever has both (non-null) "body" and "parts". To me, that suggests maybe there should be two non-abstract parse node classes, for leaf and non-leaf nodes. (The current Parse constructors would have to become factory methods.) (Later: It's not that simple. Every Parse instance has either a body or parts; also, every instance has either a trailer or more. What would it take to implement that; four derived classes, plus four interfaces? I'm still not 100% convinced, but certainly my proposed prescription is worse than the disease! Ward's LISP-based solution is better than any object-oriented solution I can think of.) --PaulChisholm
Is it really a Parsing? Or a ParseResult? Parse is so burdened with verb transitive, and Parsing is not far behind. A word with nounhood written all over it may be what the code is asking for. -- RonJeffries
In typical usage the results of parsing are tables, rows and cells. I didn't name the class any one of these because one class represents all. In the WebPageExample and FitAcceptanceTests I parse other html tags so the more specific names wouldn't apply there either.
I considered calling the class Tag since that is in common usage among web designers. But the tag proper is only a part of what the abstraction represents.
Compiler writers call these things parse nodes. I almost called the abstraction ParseNode which would certainly qualify as a noun and would be my second choice if Parse is found unacceptable. But "node" has even less descriptive weight than "manager", a term that has always annoyed me in class names.
I find "document object model" equally undescriptive though I often use the jargon word DOM when explaining Fit to people who are into that acronym. Since the abstraction is really only part of the dom, to use this terminology correctly the class would have to be called DomNode, short for document object model node.
So I end up using parse as both a noun and a verb. I don't mind that this calls attention to the class because I actually like the class a lot. I've been told that computer science graduates have been stumped by the class so maybe some attention is in order. (I also like Brian Ingerson's approach to parsing and representation a lot. More on it later.)
I almost created parse subclasses for table, row and cell. Some folks at Florida Institute of Technology explored this and showed that it enhanced readability and type checking. I drug my feet on this addition because I thought I might find better use for refinement of Parse, which I have in Fitster.
Fitster is the interactive test tool for fit. It uses an interactive refinement of Parse called (forgive me) Parster. A parster is a parse node decorator. It holds the cell annotations until you don't want them any more.
In summary, although Ron's observations are spot-on, I've been through a lot of nouns and still like parse best. As Ron would say, your millage may vary. -- WardCunningham
Return to WelcomeVisitors